线性回归
概念
线性回归是一种用于找出各个变量之间的关系的统计技术。在机器学习中 线性回归模型会找出 feature 和 label。
例如,假设我们要预测汽车的燃油效率(以英里/英里为单位)根据汽车的重量确定加仑,我们有以下数据集:
| 千磅(feature) | 英里/加仑 (label) |
|---|---|
| 3.5 | 18 |
| 3.69 | 15 |
| 3.44 | 18 |
| 3.43 | 16 |
| 4.34 | 15 |
| 4.42 | 14 |
| 2.37 | 24 |
如果我们绘制这些点,就会得到以下图表:
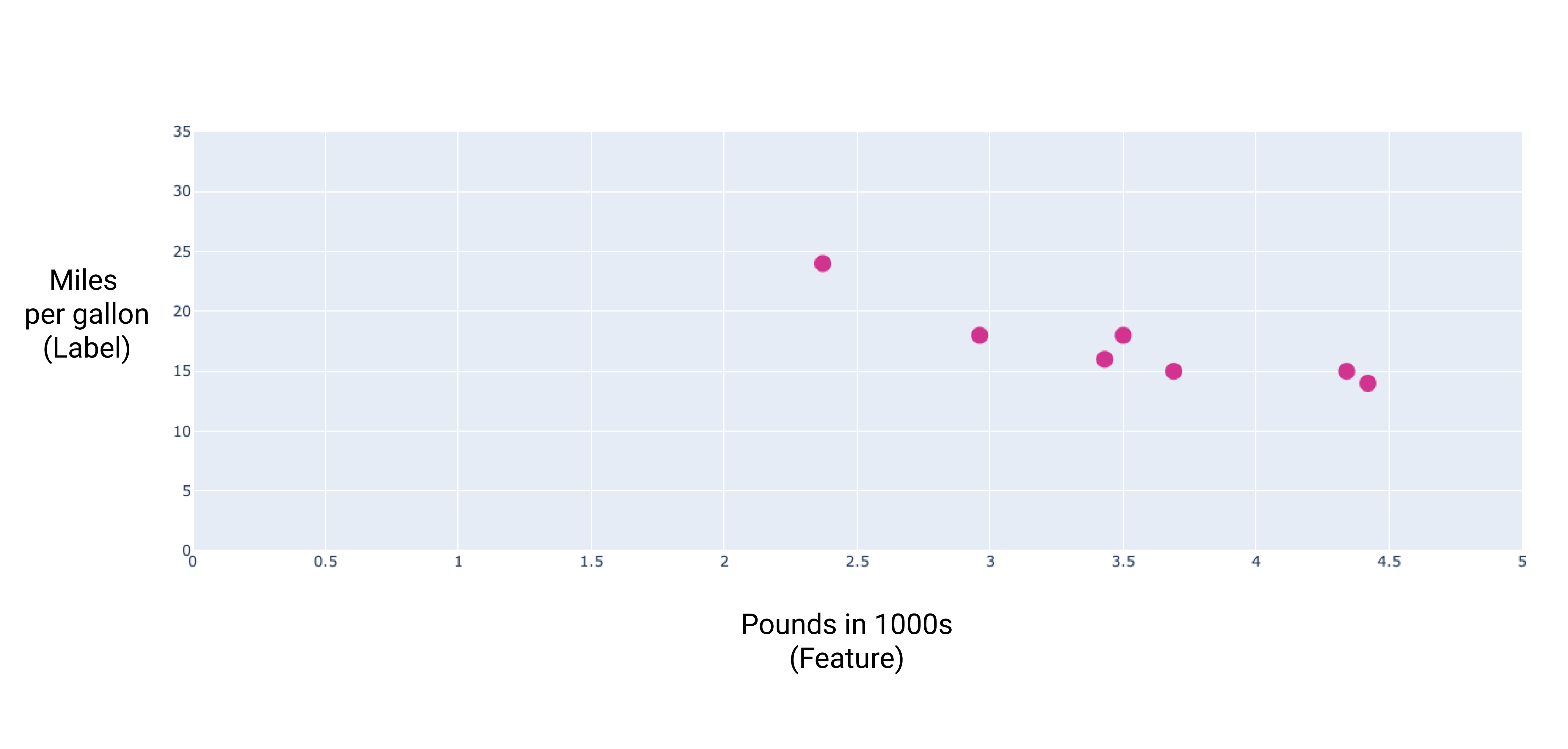
作为汽车越重,每加仑英里数的评级通常会降低。
我们可以通过这些点绘制一条最适合的直线来创建自己的模型:
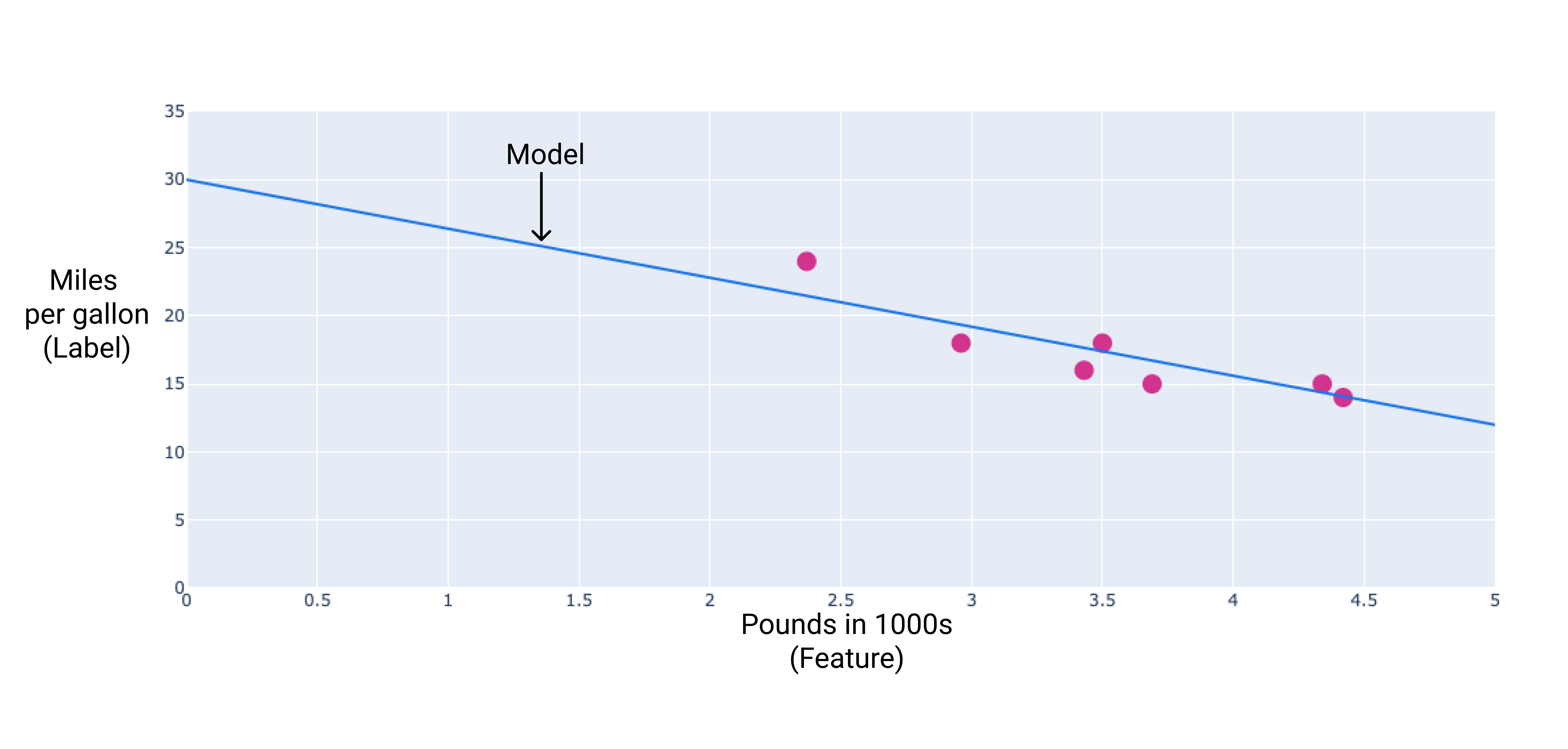
线性回归方程
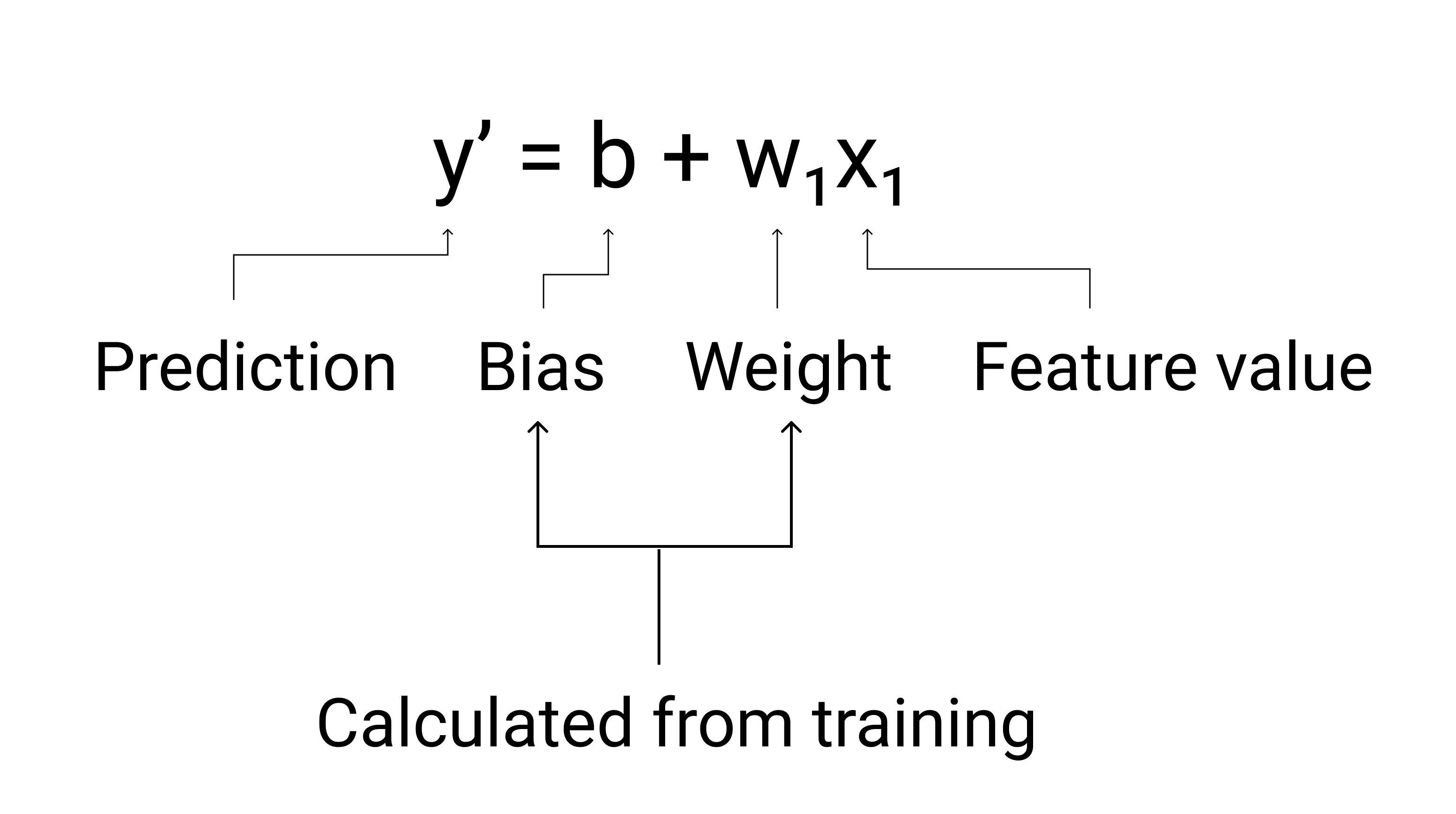
用代数术语来说,模型的定义为
在机器学习中,我们编写线性回归模型的方程式,如下所示:
其中:
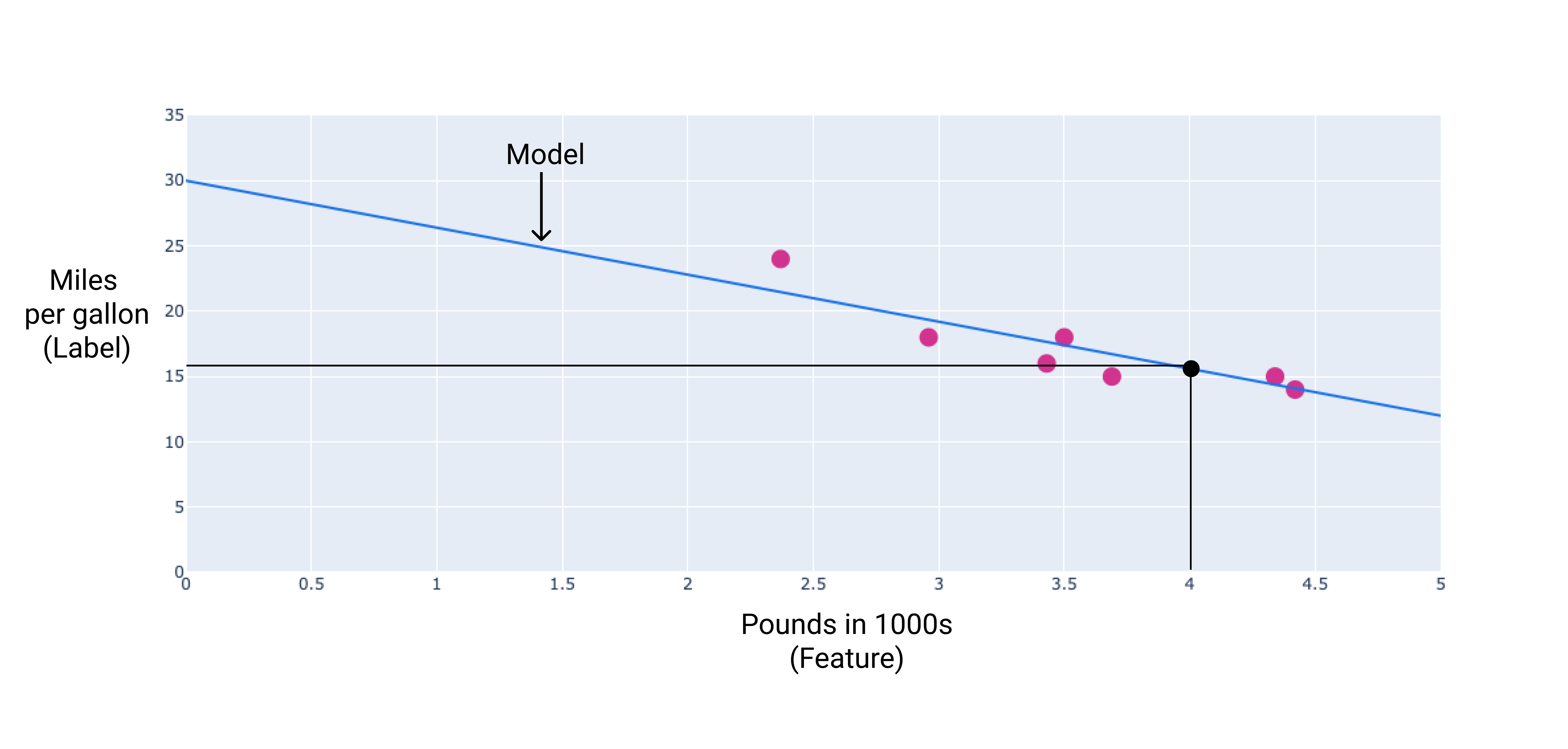
在训练期间,模型会计算可产生最佳结果的权重和偏差模型。
在我们的示例中,我们根据绘制的线条计算权重和偏差。通过偏差为 30(其中直线与 y 轴相交),权重为 -3.6( 直线的斜率)。该模型将定义为
具有多个特征的模型
虽然本部分中的示例仅使用了一项功能,即重量级汽车的特征,更复杂的模型可能依赖于多种特征, 每个都有单独的重量(
例如,预测汽油里程的模型还可以额外使用特征例如:
- 发动机排量
- 加速性能
- 汽缸数
- 马力
此模型的编写方式如下:
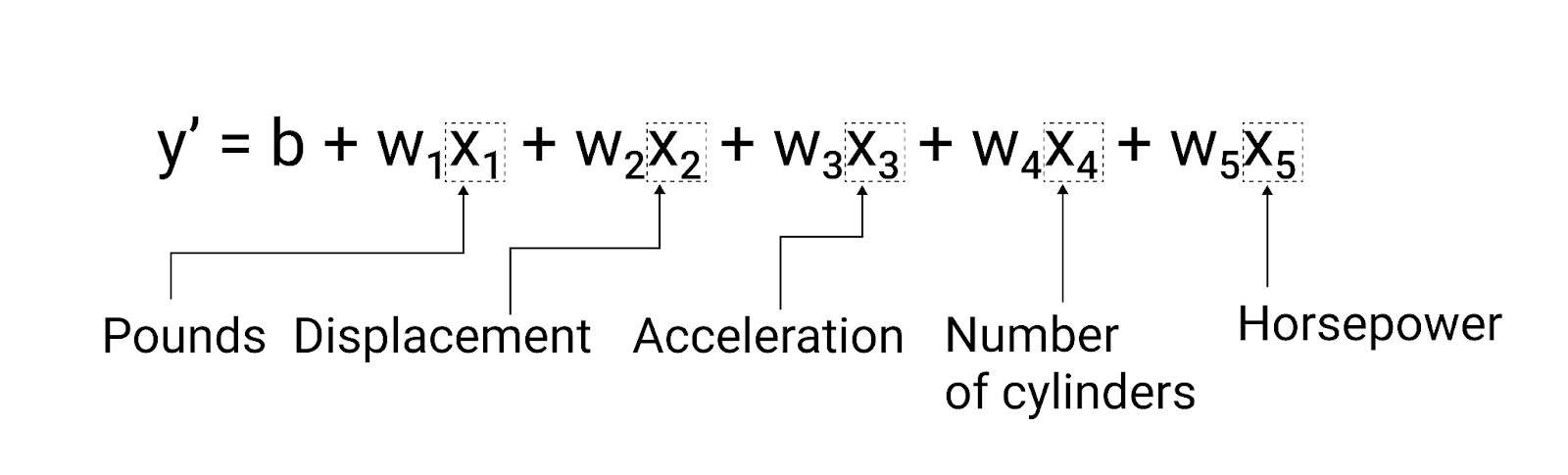
通过绘制一些附加特征的图表,可以看出它们在与 label 的线性关系(每加仑英里数):
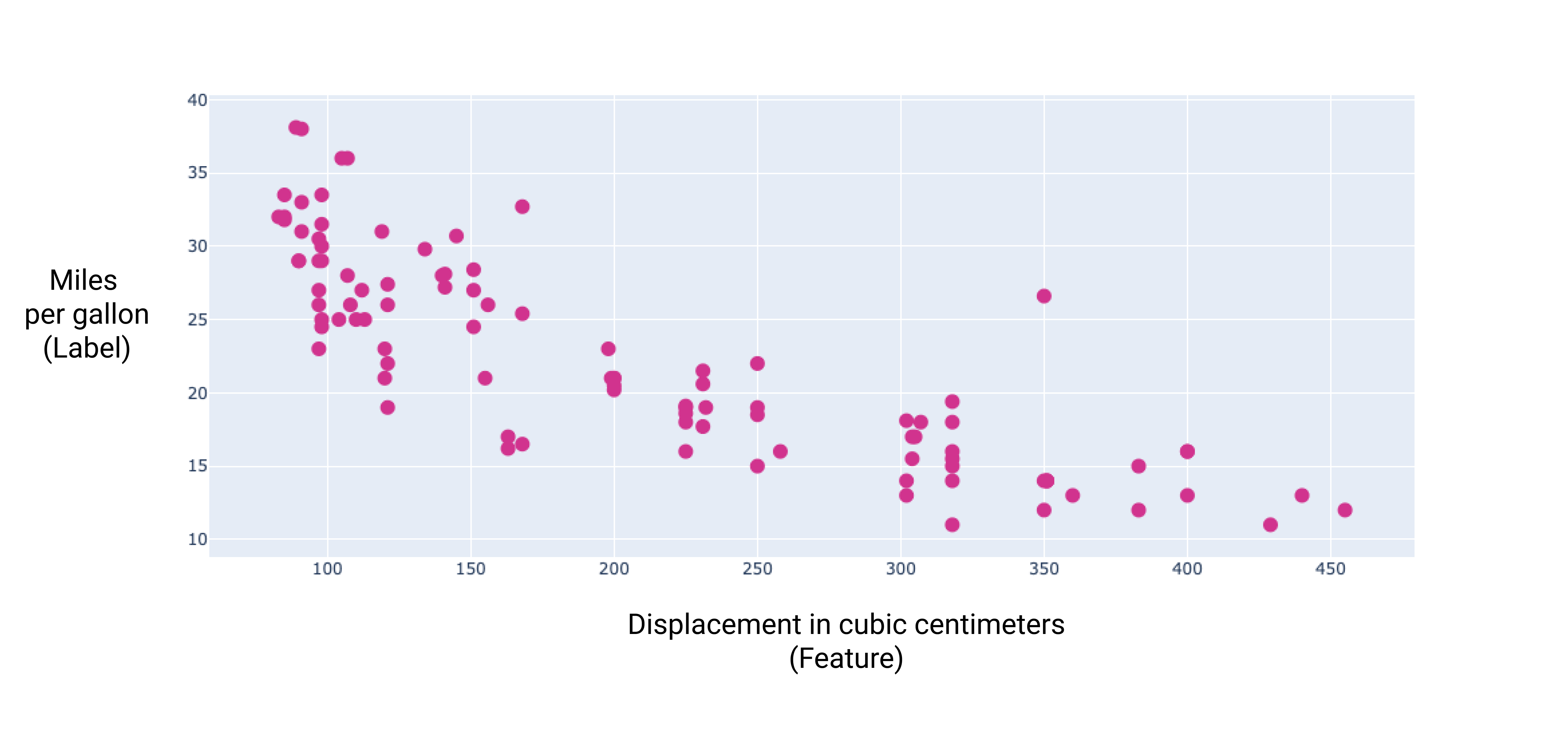
汽车的引擎加大了,每加仑的英里数评级通常会降低。
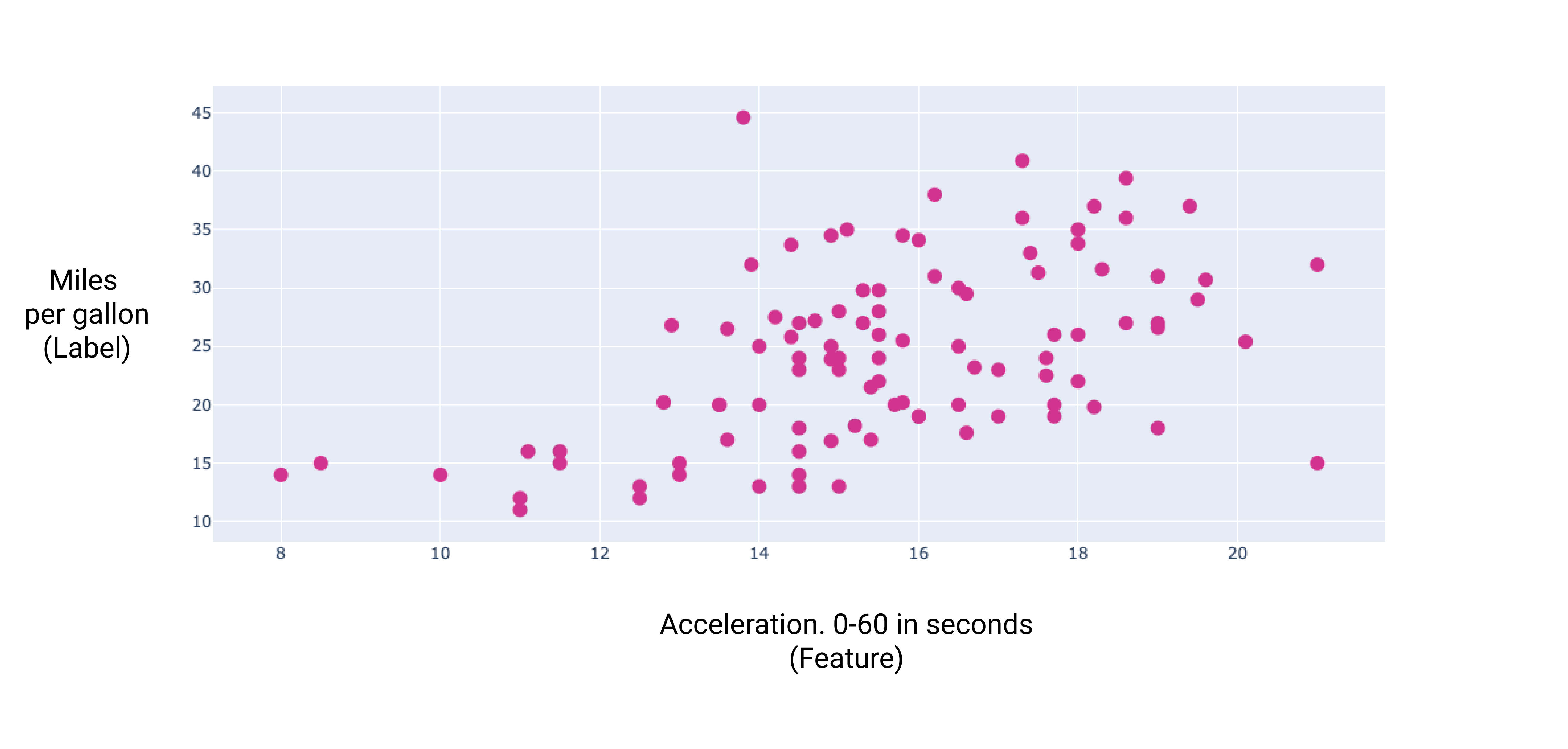 作为汽车加速用时越长,每加仑英里数通常会提高。
作为汽车加速用时越长,每加仑英里数通常会提高。
 作为汽车马力增加,每加仑英里数通常会降低。
作为汽车马力增加,每加仑英里数通常会降低。
损失
损失是一个数值指标,用于描述模型的预测有多不准确。损失函数用于衡量模型预测结果与实际label之间的距离。训练模型的目标是尽可能降低损失,将其降至最低值。
在下图中,您可以将损失可视化为从数据点指向模型的箭头。箭头表示模型的预测结果与实际值之间的差距。
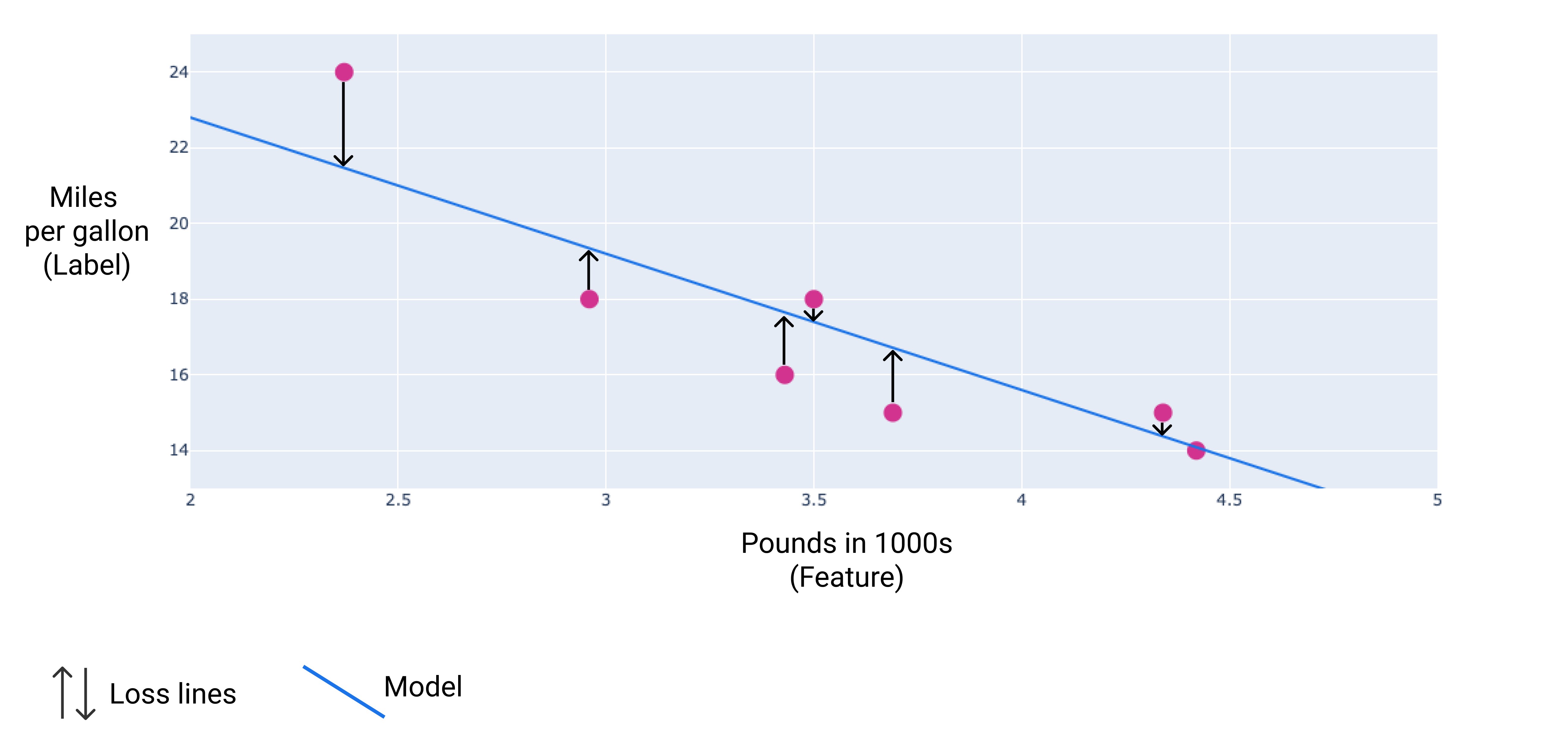
丢失距离
在统计学和机器学习中,损失函数用于衡量预测值与实际值之间的差异。损失函数侧重于值之间的距离,而不是方向。例如,如果模型预测值为 2,但实际值为 5,我们并不关心损失为负值 -3。我们关心的是这两个值之间的距离为 3。因此,所有用于计算损失的方法都会移除符号。
移除符号的最常用方法为:
- 计算实际值与预测值之差的绝对值
- 将实际值与预测值之间的差值平方
损失类型
在线性回归中,有四种主要的损失函数,如下表所示。
- 平均绝对误差(MAE),一组示例的
- 均方误差(MSE),一组样本的